主キー
データベースの主キーは、各レコード(行)を一意に識別するための特別な列です。
この主キーには一意性制約が適用されます。一意性制約とは、データベースの特定の列(フィールド)に重複する値を許さないルールを設けることです。つまり、主キーの値は同じテーブル内で重複することができません。
言い換えれば、主キーは各レコードの「身分証明書」のようなもので、それぞれのレコードに一意の「ID」を付与します。身分証明書と同様に主キーを空欄(NULLと言います)にすることは許されません。
例えば、従業員テーブルがあるとします。
| 従業員ID | 氏名 | 部署 |
|---|---|---|
| 1 | 山田太郎 | 営業 |
| 2 | 佐藤花子 | 企画 |
| 3 | 田中次郎 | 開発 |
従業員の氏名は重複する可能性がありますから、氏名を主キーとすることはできません。
しかし、各従業員に一意に発行される従業員IDは、重複することがないため、この従業員IDを主キーとして設定します。
これにより、各従業員は他の従業員と区別でき、データベース内で重複しないことが保証されます。
複合主キー
複合主キーは、複数の列を組み合わせて一意な識別子とすることで、レコードを一意に特定できるようにした主キーです。これは、単一の列だけでは一意性が確保できない場合に使用されます。
例えば、以下の「出席管理」テーブルを考えます。
出席管理テーブル:
| 日付 | 学生ID | 出席状況 |
|---|---|---|
| 2023-04-01 | 1 | 出席 |
| 2023-04-01 | 2 | 欠席 |
| 2023-04-02 | 1 | 出席 |
| 2023-04-02 | 2 | 出席 |
このテーブルでは、「日付」列だけではレコードを一意に特定できませんし、「学生ID」列だけでも一意に特定できません。
しかし、「日付」と「学生ID」の組み合わせによって、各レコードを一意に特定することができます。そのため、このテーブルでは「日付」と「学生ID」の組み合わせを複合主キーとして使用することが適切です。
複合主キーを使用することで、日付ごとに学生の出席状況を正確に追跡することができ、データの整合性が保たれます。
外部キー
外部キーは、あるテーブル内で、別のテーブルの主キーと関連付けられている列のことを指します。
これにより、2つのテーブル間で関連性を持たせることができます。このテーブル間の関連付けをリレーションと言います。
また、外部キーに参照整合性制約を使用することで、参照整合性が保たれ、データの不整合が防止されます。
例えば、次の2つのテーブルがあるとします。
従業員テーブル:
| 従業員ID | 氏名 |
|---|---|
| 1 | 山田太郎 |
| 2 | 佐藤花子 |
| 3 | 田中次郎 |
タスクテーブル:
| タスクID | タスク名 | 担当従業員ID |
|---|---|---|
| 101 | 企画立案 | 2 |
| 102 | コーディング | 3 |
| 103 | 営業戦略 | 1 |
この場合、「担当従業員ID」がタスクテーブルの外部キーとなります。
担当従業員IDは従業員テーブルの主キーである「従業員ID」と関連付けられており、タスクと従業員がリンクされています。これにより、誰がどのタスクを担当しているかがわかります。また、参照整合性制約により、存在しない従業員IDを担当従業員IDに設定することはできません。
つまり、外部キーは関連する別のテーブルの主キーを参照し、テーブル同士に関連性を持たせる働きのあるカラムだといえます。
参照整合性制約は、関連する2つのテーブルの間のデータ整合性を保つための制約のことです。
具体的には、親テーブルに存在するレコードを参照する子テーブルの外部キーに対し、存在しない値が挿入されることを防止します。
例)上の例の「タスクテーブル」の担当従業員IDには親テーブルの「従業員テーブル」に存在しない”8”のIDは入りません。
また、親テーブルのデータが変更・削除された場合、子テーブルの対応するデータも同時に変更・削除されるため、データの整合性が保たれます。
例)親テーブルである「従業員テーブル」の従業員IDが3から4に変更された場合、子テーブルである「タスクテーブル」の担当従業員IDが3の全てのレコードも同時に4に変更されます。
また、親テーブルである「従業員テーブル」の従業員IDが3のレコードが削除された場合、子テーブルである「タスクテーブル」の担当従業員IDが3のレコードも同時に削除されます。
インデックス
データベースのインデックスは、本の索引と非常によく似ています。本の索引を使えば、特定の単語や主題を素早く見つけることができます。同様に、データベースのインデックスも特定のデータを高速に検索するのに役立ちます。
テーブルの特定の列(または複数列)にインデックスを作成すると、その列に基づく検索が速くなります。
例えば、大学の学生データベースを考えてみましょう。
学生テーブル:
| 学生ID | 名前 | メールアドレス | 専攻 |
|---|---|---|---|
| 123 | 田中 | tanaka@example.com | 数学 |
| 124 | 鈴木 | suzuki@example.com | 英語 |
| 125 | 佐藤 | sato@example.com | 物理 |
| … | … | … | … |
| 999 | 渡辺 | watanabe@example.com | 哲学 |
このテーブルには何千もの行があり、特定の学生を見つけるのに時間がかかります。しかし、「学生ID」にインデックスを作成すると、データベースは特定の学生IDを直接参照することができ、検索処理が大幅に高速化されます。
さらに、「専攻」にもインデックスを作成すると、「専攻」が数学の学生をすばやく見つけることができます。これは、インデックスが「専攻」の各値に対応する学生IDのリストを保持しているからです。
ただし、インデックスはデータの挿入や更新を遅くする可能性があるため、必要な場所にだけ作成することが重要です。なぜなら、データが更新されるたびにインデックスも更新されるため、その分処理負荷が増えるからです。
また、インデックスはデータベース内に追加のデータ構造を作成するため、ディスクスペースを余分に消費します。そのため、必要な場所でのみインデックスを使用することが、効果的なデータベース管理のために重要です。
データベースのインデックスを理解するために、本を探す過程に例えてみましょう。
あなたは図書館に行って、特定の本を探しています。しかし、図書館には何千冊もの本があり、すべての本を1冊ずつ見ていくのは非常に時間がかかるでしょう。そこで、図書館員が整理した「目録」を使うことで、効率的に目的の本を見つけることができます。この目録が、データベースのインデックスに相当します。
データベースのインデックスは、テーブル内のデータを効率的に検索できるように整理された目録のようなものです。インデックスを作成することで、データベースは特定の条件に一致する行を素早く見つけることができます。この結果、検索速度が向上し、全体のパフォーマンスが改善されます。
ただし、インデックスを過剰に作成すると、データの追加や更新の際にインデックスも更新する必要があるため、逆にパフォーマンスが低下することがあります。そのため、インデックスは適切な列に対して作成し、効率的な検索を実現することが重要です。
E-R図
E-R図(Entity Relationship Diagram:エンティティ・リレーションシップ図)は、データベースの構造を視覚的に表現するためのモデリング手法で、データベース設計のために用いられます。
主に以下の要素から構成されています。
- エンティティ:データベースに格納される実体を表します。これは、オブジェクトや概念であり、データベース内で識別可能なものです。例:顧客、商品、注文など。
- リレーションシップ:エンティティ間の関連性を表します。これは、エンティティ同士がどのように関連しているかを示します。
リレーションシップには、主に以下の3つのパターンがあります。
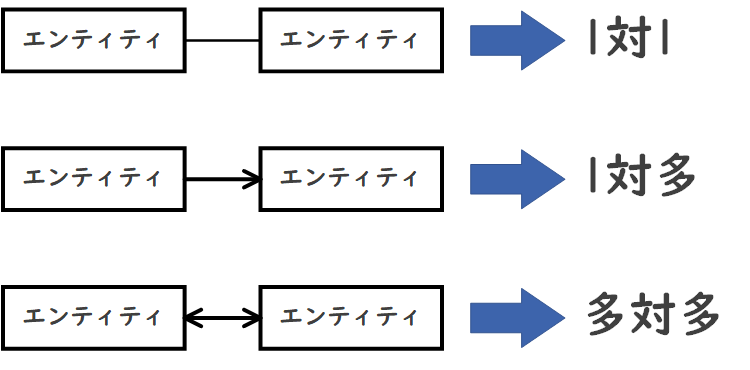
「1」の方は直線で、「多」の方は矢印で表現します。具体的な例を以下に示します。
1対1(1:1)
1つのエンティティが別のエンティティと1対1の関係を持つ場合。
例:1人の社員は1つの社員番号を持ち、1つの社員番号は1人の社員に割り当てられる。

1対多(1:多)
1つのエンティティが複数の別エンティティと関連する場合。
例:1人の顧客が複数の注文を持ち、各注文は1人の顧客に属する。

多対多(多:多)
1つのエンティティが複数の別エンティティと関連し、逆もまた同様である場合。
例:1人の学生が複数の科目を履修し、各科目は複数の学生に属する。

E-R図を使用することで、データベースの構造を把握しやすくなり、効率的な設計が可能になります。また、データベースの設計者と利用者が共通の理解を持つことができるため、コミュニケーションの効率も向上します。
E-R図の利用の具体例
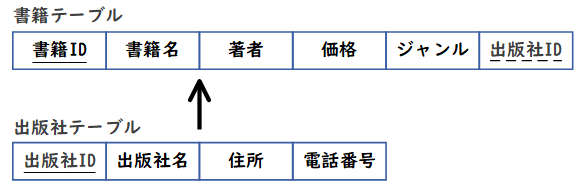
E-R図の利用の目的は、顧客や注文などといった業務の管理対象間の関係を図示し、その業務上の意味を明らかにすることです。具体例として、「書籍」エンティティと「出版社」エンティティのE-R図を考えてみましょう。
ここでは、1つの出版社が複数の書籍を出版することができ、各書籍は1つの出版社によって出版されるものとします。
すると、E-R図は以下のようになります。

このように、E-R図を作成して分析を行った後は、データベースとして管理する必要のあるデータ項目をリストアップします。これによりエンティティとデータ項目の間の関連性が明確になります。
次に、各表(テーブル)の設計を進めていきます。この段階では、属性の定義、主キーの選定、外部キーによるリレーションシップの表現など、実際のデータベース実装に向けた詳細な分析が求められます。
以下はE-R図から設計された各テーブルの図です。図中において、下線のうち実線は主キーを、破線は外部キーを表します。
関連項目
データクレンジングとは、データベースやデータセットの中から誤ったデータや不完全なデータ、重複したデータ、不適切なデータ等を見つけて修正または削除するプロセスです。
データクレンジングの目的は、データの品質を向上させ、分析や意思決定の精度を高めることであり、このプロセスを通じて、データの一貫性や正確性が確保されます。
データクレンジングには、手動のチェックや自動化されたアルゴリズムを使用することが一般的で、企業や組織がデータ駆動の戦略を採用する上で欠かせない作業となっています。
以下は、具体的なデータクレンジングの例です。
- スペリングの修正: 顧客データベース内の誤字や脱字を検出し、修正する。
- 重複の削除: 同じ顧客情報がデータベースに複数回登録されている場合の重複を検出し、不要な重複を削除する。
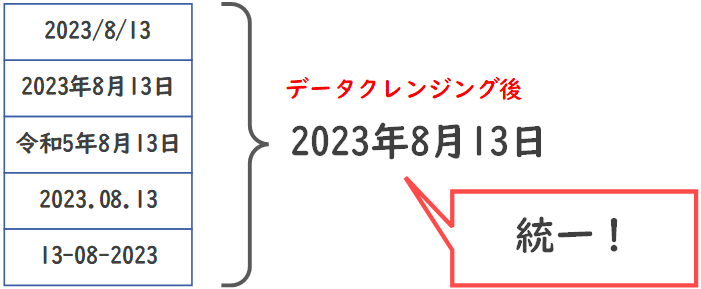
- フォーマットの統一: 日付や電話番号などのフォーマットが異なる場合、統一されたフォーマットに変換する。
- 欠損データの補完: 欠損しているデータを推測または平均値などで補完する。
- 外れ値の処理: 統計的に異常な値(外れ値)を検出し、適切に処理する。
- 不適切なデータの除去: 年齢が0や負の値で登録されているなど、不適切なデータを見つけて修正または削除する。
- 参照データとの照合: 外部の信頼できるデータソースと照合し、不整合がないか確認する。
データクレンジングは、データの内容や目的に応じてこれらの方法を組み合わせて実施することが一般的で、データ分析の精度と効率を高めるための重要なプロセスです。
※クレンジング(cleansing)は「洗浄」「掃除」「クリーニング」「清掃」を意味する英単語です。
名寄せは、異なるデータソースやデータセットに分散している情報を統合し、一貫性と正確性を確保するプロセスです。
具体的には、顧客データベース内の重複するレコードを識別し、統合する作業を指します。
例えば、「田中太郎」や「田中 太郎」、「Tanaka Taro」といった異なる表記で同一人物を指している可能性があるデータをマッチングさせ、正確な顧客情報を一つにまとめます。
名寄せは、データのクレンジング、データマイニング、CRM(顧客関係管理)などの分野で非常に重要です。このプロセスは、データの信頼性を高め、効果的なデータ分析を行う基盤を提供します。
また、名寄せは、金融機関において特に重要です。
これは、同一の顧客で複数の口座をもつ個人や法人について、 氏名又は法人名、生年月日又は設立年月日、電話番号、住所又は所在地などを手掛かりに集約し、顧客ごとの預金の総額を正確に把握するプロセスです。
名寄せを通じて、金融機関は顧客の全体像を正確に把握し、信用リスクの評価、適切な商品の提案、そして規制遵守(たとえばマネーロンダリング防止)などの業務を効率的に実行できます。