データベース
データベース(DB:DataBase)とは、データを効率的に蓄積し、管理するためのシステムです。
データの重複や不整合を避け、必要な情報を効率的に検索したり、更新したりすることができます。
例えば、企業の顧客情報や在庫管理、Webサイトの記事やユーザー情報などがデータベースに格納されています。
データベースという言葉は、もともとアメリカ軍の軍事用語で、「データの基地」という意味がありました。
初期には「data base」と2つの単語に分かれていましたが、次に「data-base」とハイフンで繋がれる形に進化し、最終的に現在の「database」という1つの単語にまとまりました。
データベース管理システム
データベース管理システム(DBMS:Database Management System)は、データの効率的な管理・操作・保護を行うソフトウェアです。
データの追加、更新、削除、検索などを行い、データの整合性やセキュリティを保つほか、アクセス権管理、障害回復、同時実行制御などの機能を持ちます。また、SQLなどのクエリ言語を使ってデータにアクセスできます。
DBMSには関係データベース管理システム(RDBMS)、オブジェクト指向データベース管理システム(OODBMS)、NoSQLデータベース管理システム(NoSQL DBMS)など、さまざまな種類があります。用途に応じて選択されるシステムが異なります。
関係データベース(リレーショナルデータベース)
関係データベース(RDB:Relational DataBase:リレーショナルデータベース)は、データを表(テーブル)の形で管理するデータベースです。データは行(レコード)と列(フィールド)の2次元の表形式で構成されます。
例えば、以下のようなオンラインショップの商品と注文の管理を考えてみましょう。
表1:products(商品)
| id | name | price | stock |
|---|---|---|---|
| 1 | Tシャツ | 2000 | 100 |
| 2 | スニーカー | 8000 | 50 |
表2:orders(注文)
| id | product_id | customer_name | quantity |
|---|---|---|---|
| 1 | 1 | 田中太郎 | 2 |
| 2 | 2 | 鈴木花子 | 1 |
上記の例では、「products」テーブルには商品の情報(id、名前、価格、在庫数)が、「orders」テーブルには注文の情報(id、商品ID、顧客名、数量)が格納されています。
また、関係データベースでは、データを効率的に検索・操作するために、SQL(Structured Query Language)という言語を使用します。
例えば、productsテーブルから在庫が50以下の商品の名前と在庫数を取得する場合、次のようなSQLクエリを実行します。
SELECT name, stock FROM products WHERE stock <= 50;
このクエリにより、productsテーブルから、stockが50以下の商品の名前と在庫数が取得されます。
| name | stock |
|---|---|
| スニーカー | 50 |
関係データベースは、データの整理や検索が容易であり、多くのアプリケーションで広く使用されています。
関係データベースの表・行・列には様々な呼び方があります。以下はその例です。
| 表 | テーブル |
| 行 | レコード、ROW、タプル |
| 列 | フィールド、属性、項目、カラム(COLUMN) ※Columnは元々「円柱」の意味があります。つまり表の縦方向です。 |
また、行と列の方向が分からなくなってしまった場合は、漢字にヒントが隠されています。よく眺めてみてください。

NoSQL
NoSQL(Not only SQL)は、従来の関係データベースに対する代替手段で、大量のデータや非構造化データを効率的に管理します。
拡張性や柔軟性に優れており、テーブル構造にとらわれないデータモデリングが可能です。
主なタイプにはキーバリューストア、ドキュメント指向データベース、グラフ指向データベース、カラム指向データベースがあり、用途や要件に応じて選択・利用されます。
NoSQLは大量のデータを高速に処理するWebアプリケーションなどに適しています。
NoSQLの種類
キーバリューストア
キーバリューストア(Key-Value Store)は、最もシンプルな形式のデータベースで、データを「キー」(Key)と「値」(Value)のペアとして保存します。各キーはユニークで、特定の値に対応しています。
この構造のおかげで、キーバリューストアは特定のキーに対応する値を素早く取り出すことができます。データ構造がシンプルなため、操作が高速で、スケールも容易です。
一般的な用途としては、キャッシュの保存、設定ファイルの管理、一時的なデータの格納などが挙げられます。RedisやAmazon DynamoDBなどがキーバリューストアの例です。
| key | value |
|---|---|
| ユーザーID1 | 田中太郎 |
| ユーザーID2 | 鈴木花子 |
| ユーザーID3 | 佐藤健一 |
| 商品コードA001 | りんご |
| 商品コードA002 | みかん |
| 商品コードA003 | バナナ |
| オーダーID1001 | 処理中 |
| オーダーID1002 | 発送済み |
| オーダーID1003 | キャンセル |
# Redis設定ファイル
# サーバーのポート番号
port 6379
# 認証用パスワード
requirepass mysecretpassword
# データベースの数
databases 16
# データの永続化設定
appendonly yes
appendfsync everysec
# ログレベル
loglevel notice
# ログファイルのパス
logfile /var/log/redis/redis-server.log
ドキュメント指向データベース
ドキュメント指向データベースは、データを「ドキュメント」として保存するデータベースシステムです。ドキュメントはJSONやXMLのようなフォーマットで表現され、階層的なデータ構造を持つことができます。
このタイプのデータベースでは、各ドキュメントが一意のキーに関連付けられ、そのキーを使用してデータを取り出すことができます。ドキュメントは柔軟で、自由なデータ構造を持つことができます。
ドキュメント指向データベースは、階層的なデータ構造や多様なデータ形式を扱う場合に特に便利です。一般的な例としては、MongoDBやCouchbaseが挙げられます。

{
"userId": "123",
"name": "山田太郎",
"age": 25,
"address": {
"city": "東京",
"postalCode": "100-0001"
},
"phoneNumbers": ["03-1234-5678", "090-1234-5678"]
}
以下の例の場合、カテゴリ(category)は階層構造のルートで、その下に商品のリスト(products)が階層化されています。
{
"category": "Books",
"products": [
{
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"price": 10.99
},
{
"title": "To Kill a Mockingbird",
"author": "Harper Lee",
"price": 8.99
}
]
}
グラフ指向データベース
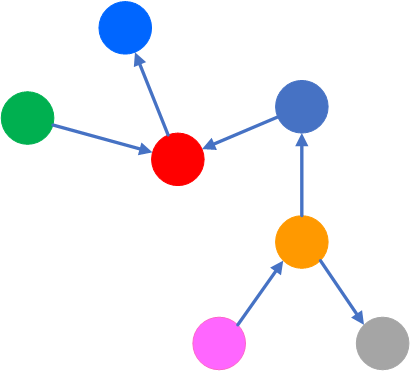
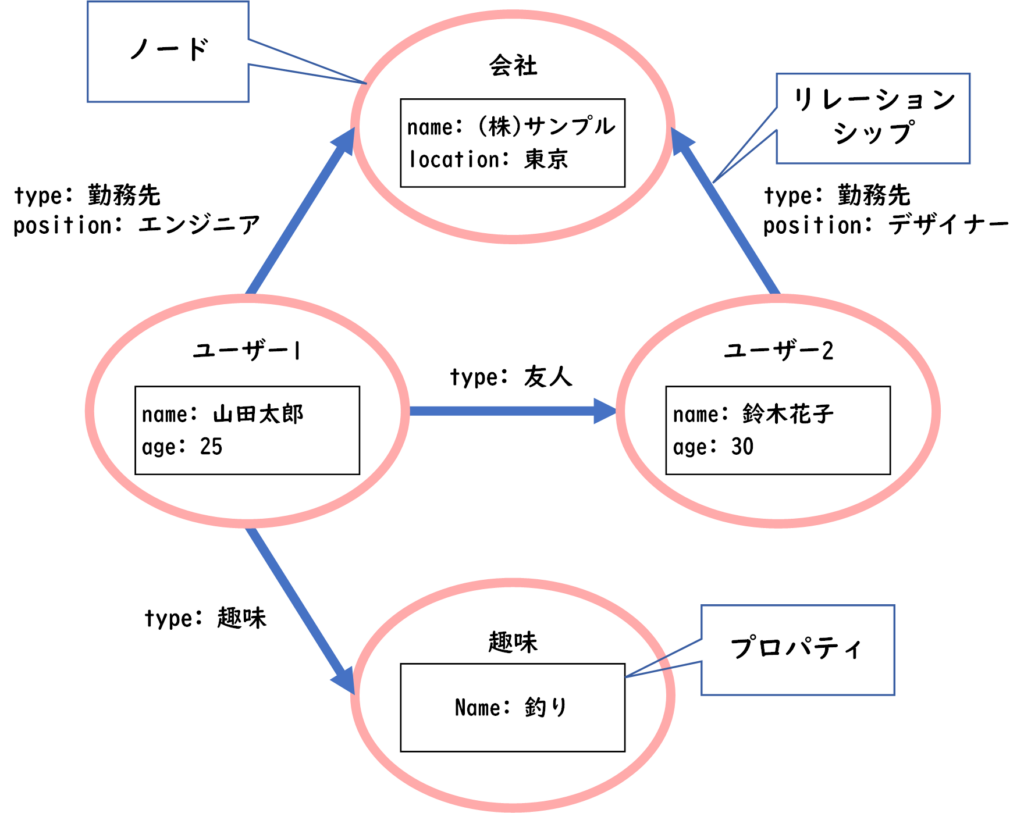
グラフ指向データベースは、エンティティ(ノード)とそれらの間の関係(エッジまたはリレーションシップ)をグラフの形で表現し、保存するためのデータベースシステムです。ノードはエンティティを、エッジはエンティティ間の関連を表します。
このタイプのデータベースは、相互に関連する多くのエンティティを持つ複雑なデータ構造を表現するのに適しています。エッジは、方向性と重みを持つことができ、これにより関係の性質と強さを表現します。
グラフ指向データベースの一般的な用途は、ソーシャルネットワーキング、推薦システム、フローネットワークの分析など、エンティティ間の関係が中心となる場合です。一般的なグラフ指向データベースにはNeo4jやOrientDBなどがあります。
カラム指向データベース
カラム指向データベースは、データを列(カラム)ごとに保存するデータベースの形式です。
関係データベースなどの通常の行指向型データベースとは異なり、各カラムごとに個別にデータが保存されるため、特定のカラムのみを効率的に取り出すことができます。
この特性は、大量のデータから特定の属性(カラム)に関する分析や集計を行うような場合に強みを発揮します。データウェアハウスや分析処理などに使われることが多いです。
例えば、顧客データベースの中から「年齢」や「地域」など特定のカラムだけを対象とした分析が必要な場合、カラム指向データベースはそのクエリの実行を高速化し、リソースを効率的に使用することができます。
| 名前カラム (Key: “Name”) | 年齢カラム (Key: “Age”) | 住所カラム (Key: “Address”) |
|---|---|---|
| ユーザー1: “山田太郎” | ユーザー1: 25 | ユーザー1: “東京都渋谷区” |
| ユーザー2: “鈴木花子” | ユーザー2: 30 | ユーザー2: “大阪府大阪市” |
| ユーザー3: “佐藤一郎” | ユーザー3: 22 | ユーザー3: “福岡県福岡市” |
関連用語
企業内の様々なデータを一元管理し、分析しやすい形に整理したデータベースのことです。
異なるソースからのデータを一箇所に集め、統一された形式に変換することで、企業全体での情報分析や意思決定をサポートします。
例: Amazon Redshift、Google BigQuery
※ウェアハウス(warehouse)には「倉庫」「貯蔵庫」などの意味があります。
BIツール(Business Intelligence Tool:ビジネスインテリジェンスツール)は、主にデータウェアハウスに蓄積された会計、販売、購買、顧客などの様々なデータ情報を用いて、データ分析やビジュアル化を行うソフトウェアです。
BIツールを用いることで、経営者などのユーザーはデータを容易に理解し、ビジネスの意思決定をより根拠に基づいたものにすることができます。
例えば、売上や顧客行動の分析結果は、ダッシュボードやグラフ、表などの視覚的な形で表示され、戦略的な意思決定を行うために利用されます。
例: Tableau、Power BI
エンタープライズサーチは、企業内の複数のデータソース(情報源)から情報を検索する技術のことを指します。
これには、社内のデータベース、ファイルサーバー、メール、社内ウェブサイト、クラウドサービスなど、あらゆる種類のデータソースが含まれます。
エンタープライズサーチの目的は、情報が分散して保存されている状況でも、必要な情報を迅速に見つけ出すことで、業務の効率化を図ることです。
例: Elasticsearch、Apache Solr
※エンタープライズ(enterprise)には「企業」「事業」「企画」などの意味があります。
データレイクは、構造化データだけでなく、非構造化データや半構造化データを含む多種多様なデータをそのままの形式で一箇所に大量に蓄積するデータストレージの概念です。
データウェアハウスが事前に構造化・整理が必要なのに対し、データレイクは「そのままのデータ」を保存するため、分析や利用の目的が明確でなくとも保管が可能です。後から必要に応じてデータを抽出し、変換・分析する際に適切な形式に整えます。
例: Amazon S3、Azure Data Lake Storage
※レイク(lake)には「湖」「湖水」「人工池」などの意味があります。