目次
文字コード
前節でコンピュータは0と1の二進数しか扱うことができないと学びました。
では数字以外の、例えば文字などはどのように表現しているのでしょうか?
そこで登場するのが「文字コード」です。文字コードは、コンピュータ上で文字や記号を表現するために使われる数値のコードのことです。
コンピュータは、電子データを二進数(0と1のみで構成される数値)で表現・処理するため、文字も同様に数値で表す必要があります。
文字コードは、それぞれの文字や記号に一意の数値を割り当てることで、コンピュータが文字情報を識別・処理できるようにします。
以下は、ASCII(アスキー)コードの対応表です。この表を参考にすると、「A」という文字は、「01000001」(10進数で65)という数値と対応づけられていることが分かります。
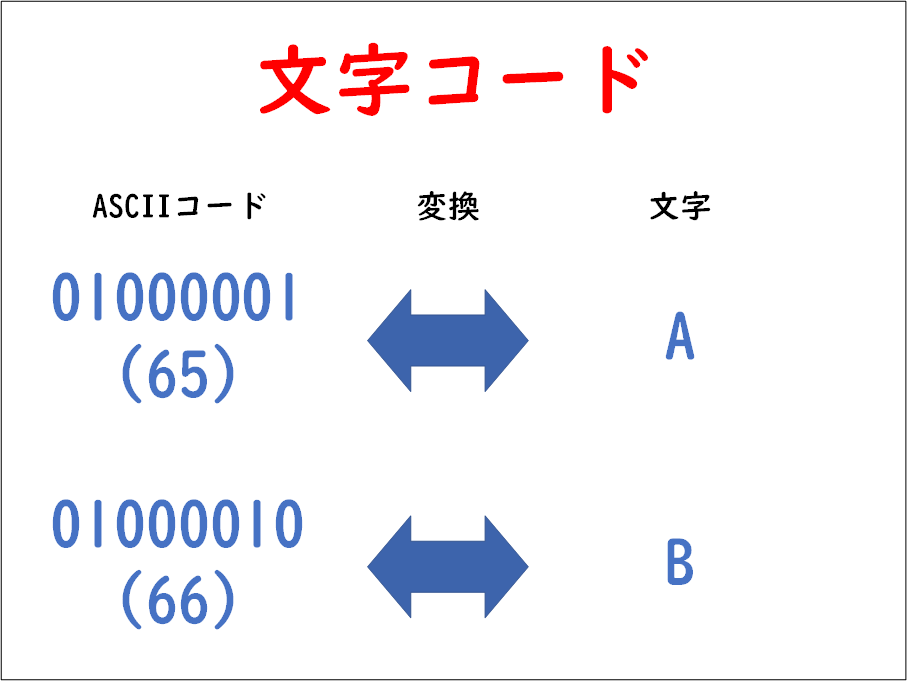
以下のASCIIコード表で、AとBはそれぞれ赤い部分に該当します。
| 上位3ビット | |||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||||||
| 下位4ビット | 0 | NUL | DLE | SP | 0 | @ | P | ` | p | ||||||||
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q | |||||||||
| 2 | STX | DC2 | “ | 2 | B | R | b | r | |||||||||
| 3 | ETX | DC3 | # | 3 | C | S | c | s | |||||||||
| 4 | EOT | DC4 | $ | 4 | D | T | d | t | |||||||||
| 5 | ENQ | NAK | % | 5 | E | U | e | u | |||||||||
| 6 | ACK | SYN | & | 6 | F | V | f | v | |||||||||
| 7 | BEL | ETB | ‘ | 7 | G | W | g | w | |||||||||
| 8 | BS | CAN | ( | 8 | H | X | h | x | |||||||||
| 9 | HT | EM | ) | 9 | I | Y | i | y | |||||||||
| A | LF | SUB | * | : | J | Z | j | z | |||||||||
| B | VT | ESC | + | ; | K | [ | k | { | |||||||||
| C | FF | FS | , | < | L | \ | l | | | |||||||||
| D | CR | GS | – | = | M | ] | m | } | |||||||||
| E | SO | RS | . | > | N | ^ | n | ~ | |||||||||
| F | SI | US | / | ? | O | _ | o | DEL | |||||||||
代表的な文字コード
世界には様々な文字があることから、文字コードも複数存在します。ここでは代表的な文字コードを紹介します。
| ASCII(アスキー) コード | ASCII (American Standard Code for Information Interchange) は1963年に制定された、アメリカ合衆国における情報通信用の文字コードです。 7ビットを使用して128の文字を定義しており、これには英字(大文字と小文字)、数字、基本的な句読点、制御コード(改行やタブなど)が含まれます。基本的な英語の文書を表現するためには十分ですが、アクセント記号や他の言語の文字を表現する能力はありません。 例えば、大文字の「A」はASCIIで65(または16進数で41)と表されます。 |
| EUCコード | EUC(Extended UNIX Code)は、主にUNIX環境で使用される文字コードで、ASCIIと互換性を持ちつつ、日本語(主に漢字)などの多バイト文字を表現することができます。 多くのEUCコード(例えばEUC-JP、EUC-KR、EUC-CN)が存在し、それぞれ異なる言語や文字セットをカバーしています。 |
| Unicode | Unicodeは、文字コードの国際標準で、世界中のほぼすべての文字を一つの統一された文字コード体系で表現することを目指しています。 各文字は固有の番号(コードポイント)を割り当てられており、ラテン文字、キリル文字、アラビア文字、中国語・日本語・韓国語の漢字など、多様な文字をカバーしています。Unicodeにより、様々な言語のテキストを一つの文書内で混在させることが可能になります。 Unicodeでは、たとえば英字の「A」はU+0041と表され、日本語の「あ」はU+3042と表されます。 |
| JISコード | JIS(Japanese Industrial Standards)コードは、 JIS(日本産業規格)で定めた日本語の文字コードです。 これにより、英字、数字、記号、ひらがな、カタカナ、漢字など、日本語をコンピュータで扱うための基準が設けられました。JISコードは主にEメールやウェブページなどで使用され、文字情報を2バイトで表現します。ただし、JISコードでは全ての漢字を表現することができず、また特殊な文字(絵文字等)を追加することが難しいという課題があります。 JISコードには、JIS X 0201(ASCIIとほぼ同じ)、JIS X 0208(より広範な日本語文字セット)、およびその他の標準が含まれます。各文字は固有のコードで表現されます。 |
| シフトJISコード | シフトJISは、JISコードを元にMicrosoftが開発した文字コードで、Windowsで採用されていることから、特に日本国内で広く利用されています。 ASCIIと漢字やひらがな、カタカナ等の日本語文字を含んでおり、一部の文字は1バイトで、一部の文字は2バイトで表現されています。 シフトJISは文字の追加が困難であるため、新しい文字や記号を追加する際にはUnicodeがより適しています。 |