データの正規化
データベースの正規化は、データベース設計においてデータの重複や矛盾を排除し、データの整合性を高めるプロセスです。これにより、更新、挿入、削除の際の異常を防ぎ、データの一貫性を保つことができます。
また、正規化はデータベースの設計をシンプルにし、維持管理をより効率的に行うことが可能になります。
以下に、第1正規化から第3正規化までの概要を説明します。
目的:繰り返し項目を排除し、すべての列が原子的(不可分)な値を持つようにします。このことにより、データの整合性を維持し、データの冗長性(重複)を減らします。
方法:テーブル内の繰り返し項目を別の行に移動し、必要に応じて新しいテーブルに分割します。それぞれの新しいテーブルに主キーを割り当て、元のテーブルと新しいテーブルの間に適切なリレーションシップを確立します。
目的:部分関数従属(ある非キー属性がキー属性の一部にのみ依存している)を排除し、各列が主キー全体に従属するようにします。
方法:部分的に関数従属している列を新しいテーブルに移動し、それらに適切な主キーを割り当てます。
目的:推移的関数従属(ある非キー属性が他の非キー属性に依存している)を排除し、すべての列が主キーに直接従属するようにします。
方法:推移的に関数従属している列を新しいテーブルに移動し、それらに適切な主キーを割り当てます。
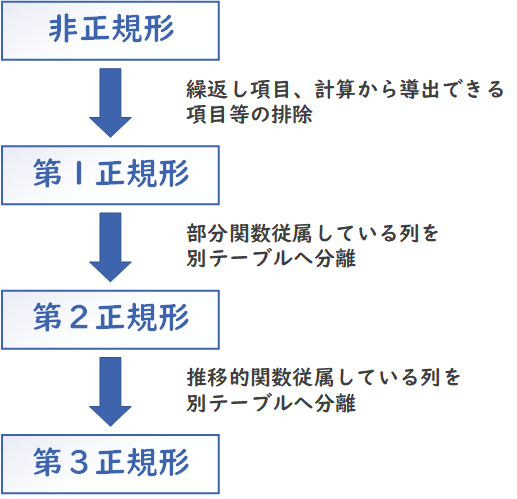
これらの正規化プロセスにより、データベースの設計が改善し、データの整合性が保たれ、データの追加・更新・削除などの操作が効率的に行えるようになります。
非正規形
下に示した注文テーブルは非正規形のデータベースであり、以下のような問題があります。
- 顧客名が繰り返し出てくるため、顧客情報の冗長性があります。
- 商品idと商品名、単価などが繰り返し出てくるため、商品情報の冗長性があります。
- 更新時異常、削除時異常、挿入時異常のリスクがあります。例えば、顧客名を変更すると、複数のレコードを更新しなければならず、更新漏れが起こる可能性があります。
非正規形のデータベースは、データの冗長性や矛盾が発生しやすく、効率的なデータ管理が難しいという欠点があります。正規化を行うことで、これらの問題を解消し、データの整合性と効率性を向上させることができます。
| 注文ID | 受注日 | 顧客id | 顧客名 | 合計金額 | 商品id | 商品名 | 単価 | 数量 | 金額 | 商品id | 商品名 | 単価 | 数量 | 金額 | 商品id | 商品名 | 単価 | 数量 | 金額 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2023/04/21 | C001 | 山田太郎 | 8000 | S001 | スニーカー | 5000 | 1 | 5000 | S002 | Tシャツ | 1500 | 2 | 3000 | |||||
| 2 | 2023/04/24 | C002 | 佐藤花子 | 3000 | S002 | Tシャツ | 1500 | 2 | 3000 | ||||||||||
| 3 | 2023/04/26 | C003 | 鈴木次郎 | 9500 | S001 | スニーカー | 5000 | 1 | 5000 | S002 | Tシャツ | 1500 | 1 | 1500 | S003 | 帽子 | 1000 | 3 | 3000 |
| 4 | 2023/04/28 | C001 | 山田太郎 | 3000 | S003 | 帽子 | 1000 | 3 | 3000 |
第1正規形
第1正規化では、各レコードが一意であり、繰り返し項目を持たないようにすることが目的です。
非正規形の表では、1つの注文に複数の商品が含まれているため、注文IDごとに1つの商品情報に分解する必要があります。
また、「合計金額」や「金額」のような、他の列(単価と数量)から計算して導くことができる列も繰り返しを避けるために削除します。
| 注文ID | 受注日 | 顧客ID | 顧客名 | 商品ID | 商品名 | 単価 | 数量 |
|---|---|---|---|---|---|---|---|
| 1 | 2023/04/21 | C001 | 山田太郎 | S001 | スニーカー | 5000 | 1 |
| 1 | 2023/04/21 | C001 | 山田太郎 | S002 | Tシャツ | 1500 | 2 |
| 2 | 2023/04/24 | C002 | 佐藤花子 | S002 | Tシャツ | 1500 | 2 |
| 3 | 2023/04/26 | C003 | 鈴木次郎 | S001 | スニーカー | 5000 | 1 |
| 3 | 2023/04/26 | C003 | 鈴木次郎 | S002 | Tシャツ | 1500 | 1 |
| 3 | 2023/04/26 | C003 | 鈴木次郎 | S003 | 帽子 | 1000 | 3 |
| 4 | 2023/04/28 | C001 | 山田太郎 | S003 | 帽子 | 1000 | 3 |
これで、表は第1正規形になりました。表中の赤文字のフィールドが主キーです(複合主キー)。
第1正規化により、以下のような利点があります。
- 各行に一意のデータが含まれるため、データの重複や矛盾が減ります。
- 行の挿入、更新、削除が容易になります。
ただし、まだ顧客名や商品名などの冗長性が残っているため、さらに第2正規化や第3正規化を行うことで、これらの問題も解消できます。
第2正規形
第2正規化では、部分関数従属(ある非キー属性が主キーの一部にのみ依存している)を排除することが目的です。これにより、テーブル間でデータの重複を減らし、データ整合性を向上させることができます。
具体的には、第1正規形は複合主キーとして注文IDと商品IDを持ちますが、受注日・顧客ID・顧客名は注文IDのみに、商品名・単価は商品IDのみに依存しているため、これらを別テーブルに分割します。
※複合主キーではなく、主キーが1つの場合には第2正規化は基本的に達成されています。
以下のように注文テーブルと商品テーブルと注文詳細テーブルに分割されます。
| 注文ID | 受注日 | 顧客ID | 顧客名 |
|---|---|---|---|
| 1 | 2023/04/21 | C001 | 山田太郎 |
| 2 | 2023/04/24 | C002 | 佐藤花子 |
| 3 | 2023/04/26 | C003 | 鈴木次郎 |
| 4 | 2023/04/28 | C001 | 山田太郎 |
| 商品ID | 商品名 | 単価 |
|---|---|---|
| S001 | スニーカー | 5000 |
| S002 | Tシャツ | 1500 |
| S003 | 帽子 | 1000 |
| 注文ID | 商品ID | 数量 |
|---|---|---|
| 1 | S001 | 1 |
| 1 | S002 | 2 |
| 2 | S002 | 2 |
| 3 | S001 | 1 |
| 3 | S002 | 1 |
| 3 | S003 | 3 |
| 4 | S003 | 3 |
これで、テーブルは第2正規形になりました。第2正規化により、以下のような利点があります。
- データの重複がさらに減少し、データ整合性が向上します。
- テーブルの構造が単純化され、クエリのパフォーマンスが向上する場合があります。
ただし、まだ注文テーブルに顧客情報と商品情報が冗長に含まれているため、さらに第3正規化を行うことで、これらの問題を解消します。
第3正規形
第3正規化の目的は、推移的関数従属(ある非キー属性が他の非キー属性に依存している)を排除することです。これにより、データの重複をさらに減らし、データ整合性を向上させることができます。
具体的には、第2正規形の注文テーブルの顧客名(非キー属性)が顧客ID(非キー属性)に依存しています。
注文テーブルから顧客名を削除し、別のテーブルとして分割します。(顧客テーブル)
| 注文ID | 受注日 | 顧客ID |
|---|---|---|
| 1 | 2023/04/21 | C001 |
| 2 | 2023/04/24 | C002 |
| 3 | 2023/04/26 | C003 |
| 4 | 2023/04/28 | C001 |
| 顧客ID | 顧客名 |
|---|---|
| C001 | 山田太郎 |
| C002 | 佐藤花子 |
| C003 | 鈴木次郎 |
| C001 | 山田太郎 |
| 商品ID | 商品名 | 単価 |
|---|---|---|
| S001 | スニーカー | 5000 |
| S002 | Tシャツ | 1500 |
| S003 | 帽子 | 1000 |
| 注文ID | 商品ID | 数量 |
|---|---|---|
| 1 | S001 | 1 |
| 1 | S002 | 2 |
| 2 | S002 | 2 |
| 3 | S001 | 1 |
| 3 | S002 | 1 |
| 3 | S003 | 3 |
| 4 | S003 | 3 |
これで、テーブルは第3正規形になりました。第3正規化による利点は以下の通りです。
- データの重複がさらに減少し、データ整合性が向上します。
- 更新時の異常(例えば、顧客名や商品名が変更された場合に複数のテーブルを更新する必要がある)が排除されます。
- テーブルがさらに単純化され、クエリのパフォーマンスが向上する場合があります。
これで、第3正規形までの正規化ができました。
推移的関数従属は、データベースの中である属性が他の属性を通じて間接的に関数従属する関係を指します。
具体的には、属性Aが属性Bに関数従属し、属性Bが属性Cに関数従属する場合、属性Aが属性Cに関数従属することを推移的関数従属と呼びます。
例えば、「注文ID」が「顧客ID」を決定し、「顧客ID」が「顧客名」を決定する場合、「注文ID」が「顧客名」を決定することになります。
この関係が存在すると、データの冗長性や不整合を引き起こす可能性があるため、データベースの設計において正規化などの手段によって是正する必要があります。
推移的関数従属の何が問題なのかを分かりやすく説明するために、具体例を用います。
具体例:図書館の本の配置
図書館にはたくさんの本があり、効率的に管理するために以下のようなルールを設けています。
各本には「本コード」が割り振られており、この本コードを使うと「棚番号」がわかります。そして、この棚番号を使うと「棚の場所」がわかる仕組みです。
これをデータベースの関数従属に置き換えると、「本コード」が「棚番号」に関数従属し、「棚番号」が「棚の場所」に関数従属するという関係になります。
まず、推移的関数従属が存在する状態のテーブルを見てみましょう。
| 本コード | 本のタイトル | 棚番号 | 棚の場所 |
|---|---|---|---|
| 001 | プログラミング入門 | A1 | 1階北側 |
| 002 | データベース設計 | B3 | 1階南側 |
| 003 | ネットワーク基礎 | A1 | 1階北側 |
上のテーブルでは、「本コード」が「棚番号」を通じて「棚の場所」に関数従属しています。
つまり、「本コード」が「棚の場所」に間接的に関数従属しているのです。この関係があると、本コードから直接棚の場所を決定することが可能になります。
推移的関数従属の問題点
しかし、このテーブル構造では、データの冗長性が発生します。例えば、「棚番号 A1」の棚の場所が「1階北側」であることが複数の行に繰り返し記載されています。この場合、棚の場所が変更されると、すべての該当行を更新しなければならず、更新漏れがあるとデータの不整合が発生します。
正規化による是正
この問題を解決するために、データベースを正規化します。具体的には、推移的関数従属を取り除くために、テーブルを分割します。
| 本コード | 本のタイトル | 棚番号 |
|---|---|---|
| 001 | プログラミング入門 | A1 |
| 002 | データベース設計 | B3 |
| 003 | ネットワーク基礎 | A1 |
| 棚番号 | 棚の場所 |
|---|---|
| A1 | 1階北側 |
| B3 | 1階南側 |
新しいテーブル設計の利点
この新しいテーブル設計では、データの冗長性が減少します。例えば、棚の場所が変更された場合、Shelvesテーブルの該当する1行を更新するだけで済みます。これにより、データの更新が容易になり、不整合が発生するリスクが低減されます。
まとめ
最初のテーブル設計では、推移的関数従属が存在するためにデータの冗長性と不整合のリスクが高まりました。正規化によってテーブルを分割し、推移的関数従属を取り除くことで、データの一貫性と効率的な管理が実現されました。
この具体例を通じて、推移的関数従属がデータベース設計においてなぜ問題となるか、そして正規化がどのようにその問題を解決するかを理解できると思います。