データ構造
データ構造とは、コンピュータでデータを整理・格納する方法のことで、効率的なデータの操作やアクセスを可能にするために使用されます。
データ構造にはさまざまな種類があり、それぞれ異なる特性や利点があるため、使用するアプリケーションや解決したい問題に応じて適切なデータ構造を選択することが重要です。
配列
配列(Array)は、データ構造の1つで、同じ型(整数型、文字列型など)の要素が連続したメモリ領域に格納される構造です。
配列は、インデックス(通常は整数)を使って各要素にアクセスできるため、ランダムアクセス※が可能で、要素の取得や更新が高速に行えます。
※先頭のデータから順番にアクセス(シーケンシャルアクセス)するのではなく、目的のデータの場所に直接アクセスすること。
例えば、5人の生徒のテストの点数を管理したい場合、以下のように配列を利用できます。
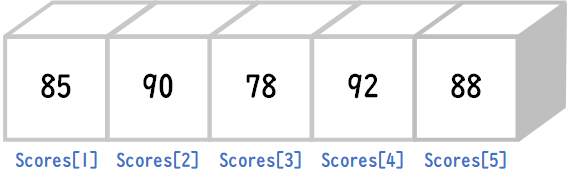
int scores[] = {85, 90, 78, 92, 88};この例では、int 型の要素を格納する配列 scores を作成し、5人の生徒の点数を順番に格納しています。
配列の要素番号(インデックスともいいます)は、最近は0から始まるプログラミング言語の方が多いですが、ITパスポートの問題では文中で「ここで、配列の要素番号は1から始まる」と指定されている場合が多いので、そちらにならいます。
したがって、scores[1] は85、scores[2] は90、scores[3] は78、といった具合に、各生徒の点数にアクセスできます。
配列の利点は、要素へのアクセスが高速であることですが、いくつかの欠点もあります。配列のサイズは固定で、宣言時に決められるため、後からサイズを変更することができません。
これは、配列に対する要素の追加や削除があまり効率的でないためです。もし仮に要素の追加が可能だとしても、要素を途中に挿入したり、削除したりする場合、他の要素を移動する必要があるため、処理が遅くなる可能性があります。
このような欠点を克服するため、動的配列や後述するリストなどの他のデータ構造が開発されています。
しかし、配列はシンプルで効率的なデータ構造であるため、固定サイズのデータを扱う場合やランダムアクセスが重要な場合には、依然として有用です。
配列は一列に整然と並べられたロッカーに例えることができます。
想像してみてください。学校やジムには、多くのロッカーが一列に並んでいて、それぞれのロッカーには番号がついています。これを配列と考えると、ロッカーの中に入れるもの(例えば、本、靴、カバンなど)が配列の各要素に相当し、ロッカーの番号が配列のインデックスに相当します。
具体的な動作を例えると:
- 「3番目のロッカーにカバンを入れる」は、配列の3番目の位置にデータを保存することになります。
- 「5番目のロッカーの中身を確認する」は、配列の5番目のデータを取り出して見ることになります。
このように、配列は順番に並べられた「格納箱」としての機能を持ち、それぞれの箱には独自の番号(要素番号:インデックス)が付与されているのです。
配列は、引き出しが上下に整然と並べられたタンスに例えることができます。
想像してみてください。タンスには多くの引き出しが上下に並んでいて、それぞれの引き出しには番号がついています。これを配列と考えると、引き出しの中に入れるもの(例えば、衣服、アクセサリー、小物など)が配列の各要素に相当し、引き出しの番号が配列のインデックスに相当します。
具体的な動作を例えると:
「3番目の引き出しにシャツを入れる」は、配列の3番目の位置にデータを保存することになります。
「5番目の引き出しの中身を確認する」は、配列の5番目のデータを取り出して見ることになります。
このように、配列は順番に並べられた「格納箱」としての機能を持ち、それぞれの箱には独自の番号(要素番号:インデックス)が付与されているのです。
- 画像処理: ピクセルデータを配列として管理し、画像を処理するために使用されます。各ピクセルの色情報を格納するために2次元配列が使われます。
- 週の予定管理: 1次元配列を使って、月曜日から日曜日までの予定を格納します。これにより、各日の予定を簡単に確認したり、更新したりできます。
- 駐車場の空き状況: 駐車場の各スペースを配列の要素として格納し、空きならば「0」、使用中ならば「1」を設定します。これにより、どのスペースが空いているかをすぐに確認できます。
その他のデータ構造
リスト(List)
要素を順番に連結して格納するデータ構造で、各要素はポインタで次の要素への参照を保持します。
先述した配列と異なり、要素の追加や削除が容易で、サイズが動的に変更できます。
ポインタによる連結のため、ランダムアクセスは遅いですが、リストの先頭から順にアクセスするシーケンシャルアクセスがスムーズになります。

リストは列車に例えることができます。
列車は複数の車両(ノード)が連結している構造をしています。各車両は、前の車両と後ろの車両(次のノード)への接続(ポインタ)を持っています。これがまさに連結リストの基本的な構造です。
- 各車両(ノード): 連結リストにおける一つ一つの要素です。各車両は乗客(データ)を持ち、次に繋がる車両への接続(ポインタ)を有しています。
- 先頭車両(ヘッド): 列車の最初の車両に相当します。リストにおいては、リストの最初のノードを指します。この車両(ノード)から列車全体(リスト全体)にアクセスできます。
- 最後尾車両(テール): 列車の最後の車両です。連結リストでは、リストの最後のノードを指し、通常、次のノードへのポインタは「null」または特定の終了を示す値に設定されています。これにより、リストの終わりを示します。
- 車両の追加・削除: 列車に新しい車両を追加する場合、既存の車両間に新しい車両を挟み込み、前後の車両との接続を更新します。車両を取り除くときも、取り除かれる車両の前後の車両を直接連結させることで、列車を維持します。
このように、リストは列車のように柔軟に車両(ノード)の追加や削除が可能であり、データの一連の流れを効率的に管理することができます。ただし、特定の車両(ノード)に直接アクセスするためには、先頭から順番に辿っていく必要がある点が、配列など他のデータ構造と異なる特徴です。
- 音楽プレイリスト: ユーザーが曲を追加したり、順序を変更したりできるため、SpotifyやApple Musicなどの音楽プレイリストに使用されます。
- タスク管理アプリ: タスクの順序を保持しながら追加・削除ができるため、To-Doリストやプロジェクト管理ツールに利用されます。
キュー(Queue)
データを「先入れ先出し」(FIFO: First In First Out)の順序で格納するデータ構造です。データの追加はキューの末尾で行われ、取り出しは先頭で行われます。

キューは、スーパーマーケットのレジ待ち行列に例えることができます。お客さんが行列の最後に並び、順番にレジで会計を済ませていく様子が、まさにキューの動作原理を表しています。
- 先入れ先出し(FIFO; First In, First Out): 最初に並んだお客さんが最初に会計を済ませて行列から出ていきます。キューにおいても、最初に追加されたデータが最初に取り出されます。
- エンキュー(Enqueue): 新しいお客さんが行列の最後尾に並ぶ行為を、データ構造のキューにおける「エンキュー」と言います。これは、キューに新しい要素を追加する操作に相当します。
- デキュー(Dequeue): レジで会計が終わり、行列からお客さんが出ていく行為を「デキュー」と言います。これは、キューから要素を取り出し、それをキューから削除する操作に相当します。
このように、キューは順序を保ちつつ、効率的に要素を追加・削除するためのシンプルで強力なデータ構造です。
- プリントジョブ管理: 複数の印刷要求が順番に処理されるように、プリンターのキュー管理に使用されます。
- カスタマーサービス: コールセンターでの顧客の電話待ち行列や、ウェブサイトのチャットサポートの待ち行列管理に利用されます。
スタック(Stack)
データを「先入れ後出し」(LIFO: Last In First Out)の順序で格納するデータ構造です。データの追加(プッシュ)と取り出し(ポップ)はスタックの一番上で行われます。
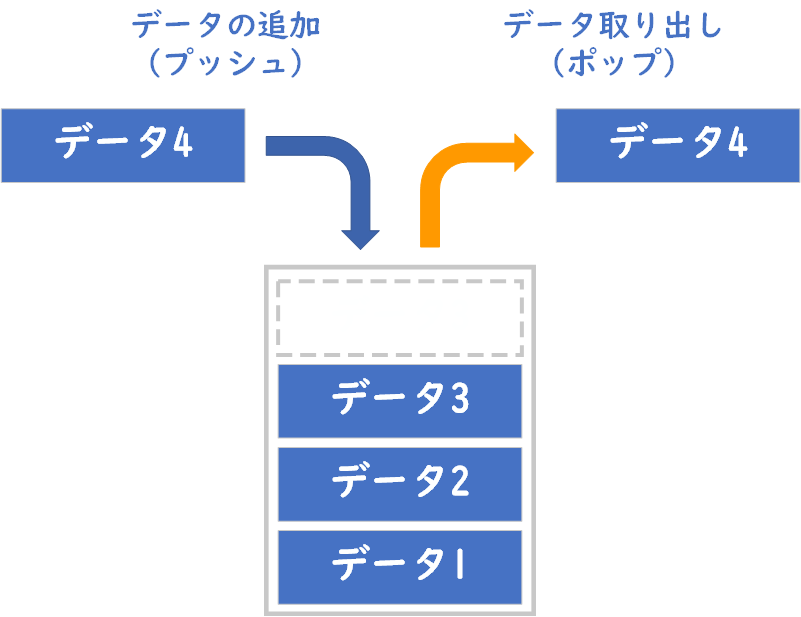
スタックは、皿を洗った後に積み上げる状況に例えることができます。洗った皿を積み上げるときは、一番下から順番に積み上げていきます。そして、皿を使いたいときには一番上から順に取っていきます。
- 後入れ先出し(LIFO; Last In, First Out): 最後に積み上げた皿が最初に使われます。スタックにおいても、最後に追加された要素(最後に洗った皿)が最初に取り出されます。
- プッシュ(Push): 新しく洗った皿を積み上げる行為が、「プッシュ」と考えられます。これはスタックに新しい要素を追加する操作に相当します。
- ポップ(Pop): 皿を使うために一番上の皿を取る行為が「ポップ」となります。これはスタックから最上部の要素を取り出し、それをスタックから削除する操作です。
このスタックの概念は、データを一時的に保管しておく必要があるさまざまなプログラミングの状況で非常に有用です。たとえば、プログラムがサブルーチンを呼び出した時の戻りアドレスの保管や、ブラウザの戻る機能でのページ履歴管理などに使われます。
- ブラウザの履歴管理: ユーザーがウェブページをナビゲートする際に、ブラウザの戻る機能で使用されます。新しいページに行くとき、スタックにページを積み、戻るボタンを押すとスタックからポップして前のページに戻ります。
- テキストエディタのアンドゥ機: テキストエディタのアンドゥ機能は、ユーザーが行った操作を取り消すためのものです。スタックを使用することで、ユーザーの操作履歴を管理し、最後の操作から順に取り消すことができます。
木構造(Tree)
木構造は、データの階層的な関係を表現するための構造です。以下の要素を持っています。
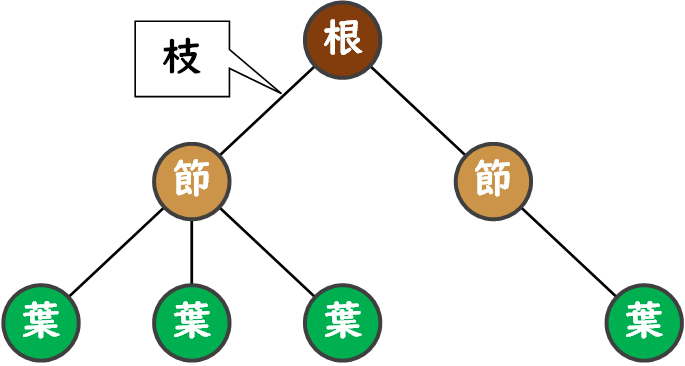
- ノード(Node): 木構造を点と線で表現したときの点。データを保持する要素としての役割を果たします。以下に説明する根、節、葉はすべてノードの一部です。
- 根(Root): 木構造の始点となる要素。一つだけ存在し、他の全ての要素はこの根を基点とした階層関係になります。
- 節: ノードの中でも、下の階層に節または葉を持つノードのこと。データの分岐点や集合点としての役割を果たします。
- 葉: 下の階層に何も持たない、終端のノードのこと。最も具体的なデータを持つ部分としての役割を果たします。
- 枝: ノードとノードを結ぶ線。データの流れや関係性を示す部分です。
このように、木構造は根から始まり、節や葉へと分岐していく形で、データ間の親子関係や順序関係を視覚的に表現することができます。
2分木
2分木は木構造の一種で、以下の特徴を持っています。
- 各ノードは最大2つの子ノード(左の子と右の子)を持つことができます。
- 2つの子ノードのうち、左側を「左子ノード」と呼び、右側を「右子ノード」と呼びます。
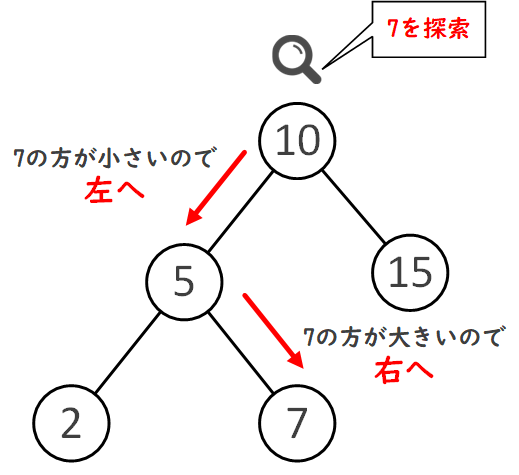
2分木の中にはさまざまなタイプがあり、それぞれ特定のルールや特性を持ちます。例えば、二分探索木は、すべてのノードについて、左の子ノードの値は現在のノードの値よりも小さく、右の子ノードの値は現在のノードの値よりも大きい、という条件を満たす2分木、つまり「左子ノード < 親ノード < 右子ノード」となっている2分木です。
二分探索木は、データの迅速な検索、挿入、削除を目的として使われます。階層的なデータ構造を持つため、平均的な状況での探索や操作が高速に行える特徴があります。
例えば下の二分探索木で「7」を探す場合、ルートから順に探索対象の7と比較していき、7の方が小さければ左へ、大きければ右へ移動していけば目的のデータにたどり着くことができます。
WindowsやmacOSのファイルシステムは木構造を採用しています。
ファイルシステムにおける木構造は、ディレクトリ(またはフォルダ)とファイルから成り立っています。最上位にあるディレクトリをルートディレクトリと呼び、それ以下にサブディレクトリやファイルが階層的に配置されます。
つまり、ルートディレクトリが、木構造の根(root:ルート)に相当し、サブディレクトリやファイルが節や葉に相当します。
例えば、以下は単純化されたファイルシステムの木構造の例です。
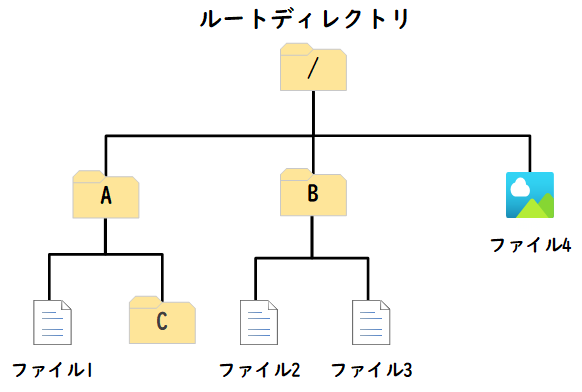
このように、ディレクトリやファイルは木構造で整理されており、これによってユーザーはデータを効率的に整理、検索、管理することができます。
Windowsの場合、各ドライブ(Cドライブ、Dドライブなど)が独自のルートディレクトリを持つことになります。macOSでは、すべてのディスクやドライブは単一のルートディレクトリにマウントされる形となります。
とはいえ、抽象的なレベルで見れば、どちらのOSもファイルシステムの背後には木構造の考え方が採用されています。